Pose-guided diffusion model
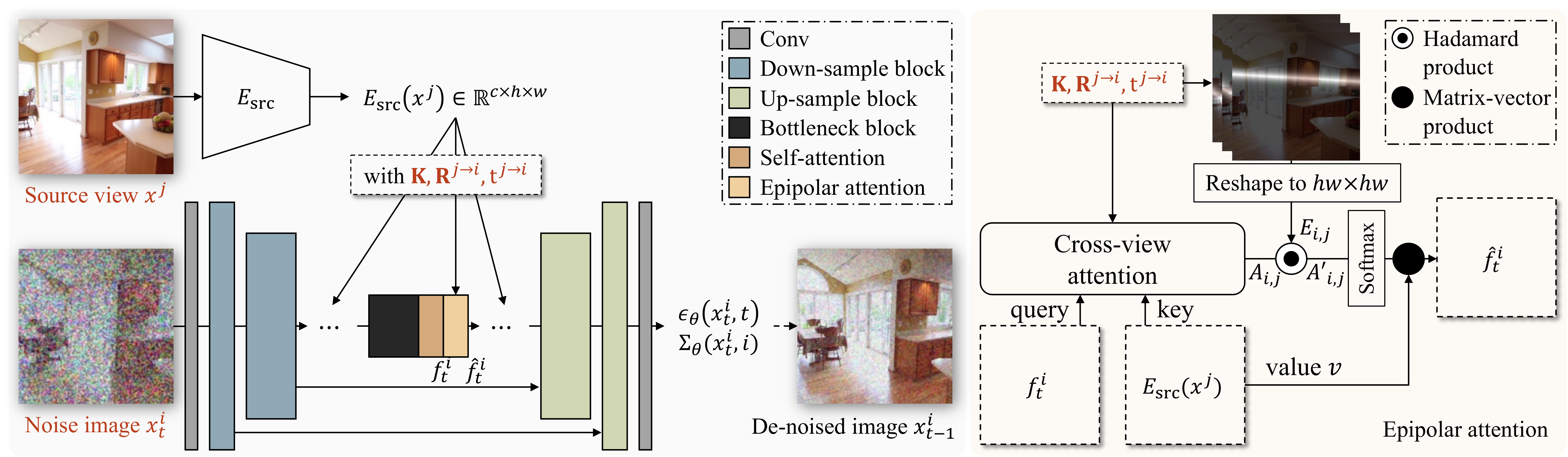
With the proposed epipolar attention that associates the target view with the source view features, the pose-guided diffusion model learns to de-noise the target view from the input source view and relative pose.
Novel view synthesis from a single image has been a cornerstone problem for many Virtual Reality applications that provide immersive experiences. However, most existing techniques can only synthesize novel views within a limited range of camera motion or fail to generate consistent and high-quality novel views under significant camera movement. In this work, we propose a pose-guided diffusion model to generate a consistent long-term video of novel views from a single image. We design an attention layer that uses epipolar lines as constraints to facilitate the association between different viewpoints. Experimental results on synthetic and real-world datasets demonstrate the effectiveness of the proposed diffusion model against state-of-the-art transformer-based and GAN-based approaches.
With the proposed epipolar attention that associates the target view with the source view features, the pose-guided diffusion model learns to de-noise the target view from the input source view and relative pose.
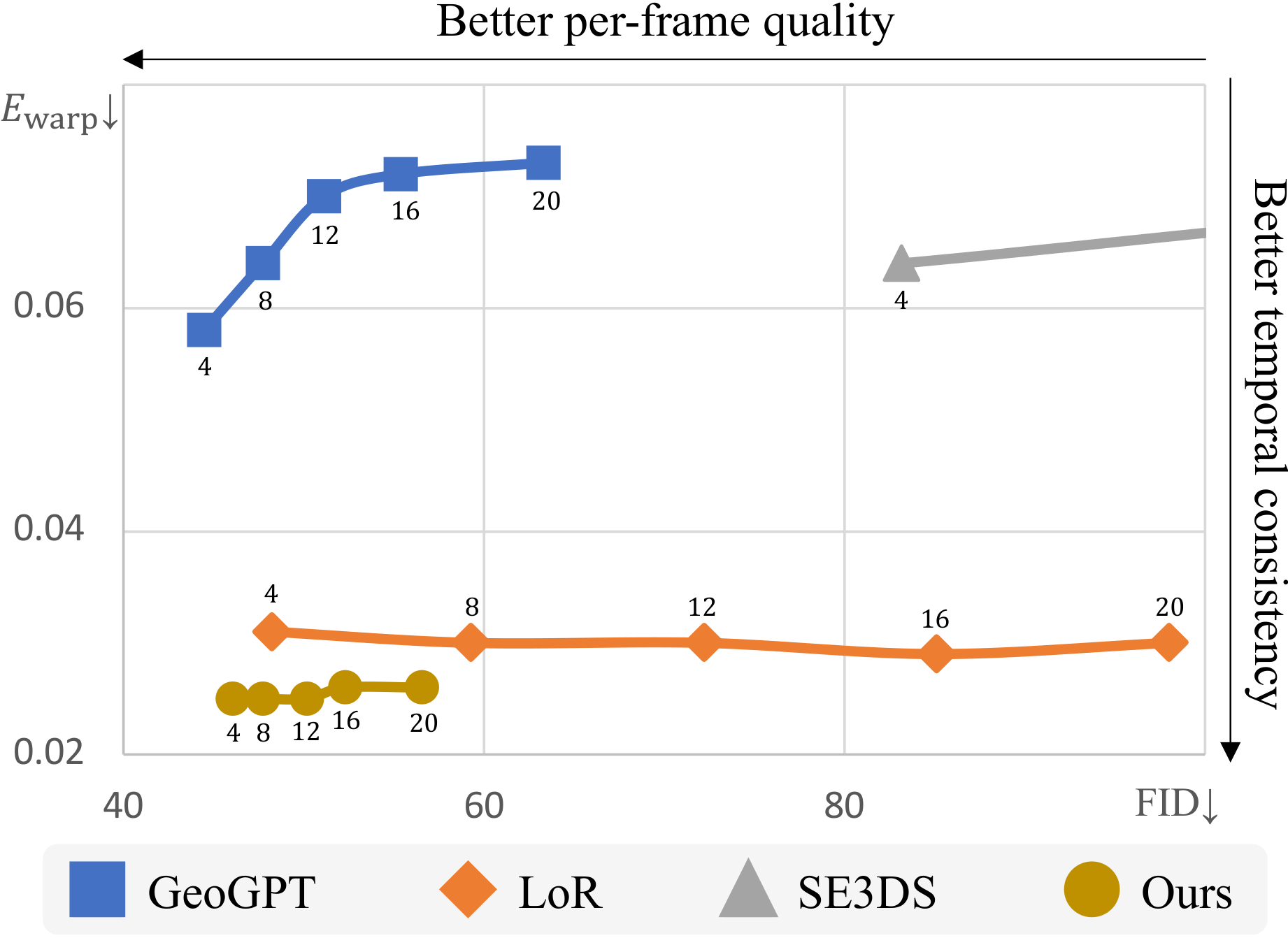
We show the FID of the last frames (per-frame quality) and flow-warping errors (consistency) given different generated video lengths {4, 8, ..., 20}. Our method generates not only realistic but also consistent novel views.
We show the comparisons between our method, GeoGPT, LoR, and SE3DS on the RealEstate10K and MatterPort3D datasets.
@inproceedings{poseguideddiffusion,
author = {Tseng, Hung-Yu and Li, Qinbo and Kim, Changil and Alsisan, Suhib and Huang, Jia-Bin and Kopf, Johannes},
title = {Consistent View Synthesis with Pose-Guided Diffusion Models},
booktitle = {CVPR},
year = {2023},
}